
Generating Waveform Data - Audio Representation
Audio visualization is a fascinating topic. We often take it for granted, but sound isn’t visible and only exists over time. In the case of a video stream, you can pick a frame/image and you have a snapshot of the video at this specific time. But you can’t do that with sound. Sound is the oscillation/vibration of molecules over time, it’s by definition a sensation and therefore not something easily visualized. In this article, I will cover the most common representation of an audio file: the waveform.
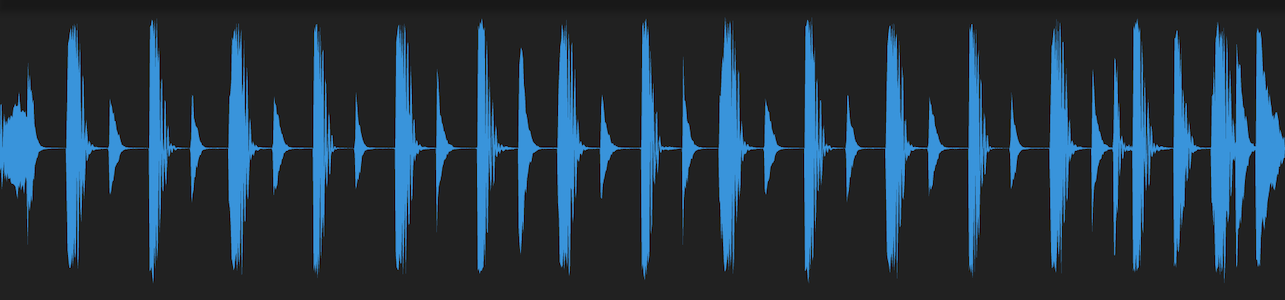
In audio, a waveform represents the amplitude of the signal over time. In other words, it shows the maximum extent of a vibration or oscillation, basically the volume of the sound over time. Note that while commonly used, it’s not the only sound representation we have and we will see that even if waveforms look alike, they are often not calculated and rendered the same way.
By the end of this article, you will understand how waveforms are generated and how to create the data you need to more easily and efficiently draw waveforms yourself.
Understanding the audio signal
In the case of a waveform, we are looking at a sound source over a certain amount of time. Usually that content comes from an audio file (or a in-memory buffer). Audio content is usually stored in two different ways: compressed and uncompressed (AKA PCM). You probably encountered .wav or .aiff files, those are uncompressed files meaning that the amplitude of the signal is stored as is in the file. On the other hand files such as .mp3, .flac or .m4a are compressed meaning that an algorithm was used to pack the content more efficiently, kind of like zipping the audio file. I covered this topic a bit more in depth in this article, but the short version is that to record audio digitally, we sample the signal x times per second (44,100 times in CD quality) and we store this information in the file so we can then re-use the data to move speaker membranes. An audio file contains the amplitude of the signal, which is exactly what we need to draw a waveform.

But there are two problems.
Compressed audio files
If you have a MP3 file, you have to first decompress its content to get the amplitude. That’s a bit problematic because it’s a CPU intensive task and the file might be big so we don’t want to keep everything in memory. A simple approach might be to convert the mp3 file into a wav file and store it to disk so we can process it. It does require however that the code cleans up after itself and if the same file is reopened/rendered later on, the expensive operation will need to happen again.
Too much data
To draw a waveform, we don’t need as much samples as when playing it back. Processing so much data is expensive and slow, especially on big files where we need to reduce the data because we have more samples that pixels to draw the waveform on. That’s why software like Ableton Live and Audacity create summary files.
“If Audacity is asked to display a four hour long recording on screen it is not acceptable for it to process the entire audio each time it redraws the screen. Instead it uses summary information which gives the maximum and minimum audio amplitude over ranges of time. When zoomed in, Audacity is drawing using actual samples. When zoomed out, Audacity is drawing using summary information.”
You can read more about Audacity BlockFiles here
Generating a summary information file
From the BBC to Soundcloud most services offering audio playback need a way to efficiently render waveforms. This is usually done by pre-calculating a summary server side when the audio file is first seen. This pre-calculated summary can then be loaded by the client at the same time (or even before) the audio file is downloaded and ready to play.
There are various ways to create a summary file and store its data. But the overall concept is always the same, we need to reduce the amount of data so we group samples together and we extract a value representing the time window we are reducing. One option is to create an average value of that window. Let’s say we group 256 samples together, we could add all the values together and then divide by 256, that would give us the average amplitude during that time period. Another option is to follow Audacity’s approach and for each window, we get the min and max values. This is less efficient from a storage perspective because we will end up with twice the data size, but it gives us more resolution on the data to draw an arguably better waveform.
Luckily for us, the BBC R&D group wrote a free and open source tool to do just that: https://github.com/bbc/audiowaveform
The audiowaveform command line tool can generate summary files in binary and json formats and can also generage waveform images but I’m not interested in this last feature since fixed size waveforms don’t go well with modern responsive UI designs.
I picked this tool because it’s free, we can dig into the source code, wrap it to be used from another programming language and the default options are great to get started. It’s also well documented, written and maintained. Finally, the BCC also released JS tools to consume the data, while you might not care to use those libraries, it’s great to have a reference implementation to understand how things work.
I would suggest to spin a web service that would receive an audio file (more likely via a GCS/S3 reference), copy the file locally and summarize it using the audiowaveform tool:
$ audiowaveform -i input.mp3 -o test.json
Then copy the json or binary data to GCS/S3 so it can be easily accessible.
The window size (by default 256 samples) depends very much on what you are going to do with the waveform and the average duration and sample rates of your audio files. Grouping 256 samples together on a 44.1KHz audio files means that we still have more than 172 data points per second. But if you deal with very short sounds it might not be enough, here is an example if a short cymbal sample, the entire file is less than 2 seconds and the hit itself last around 500ms:

(the example waveforms are rendered in a Flutter app using path drawing, the same results can be achieved on the web using canvas, more on that in a later post)
As you can see the resolution isn’t great. So we can try again by using a smaller window. Here is the same rendering but with the grouping using half the number of samples: -z 128

It’s better but we can’t really zoom in, the resolution is still quite low. Let’s try with a window of 64 samples:

That’s much better!
Note that the BCC tool is only one of the many freely available tools out there. I chose it for this article because it’s easy to use and demo. However, depending on your use case, you might prefer to do normalized averages instead. To do that, you might want use other existing tools such as SoX or FFmpeg. If you don’t care about zooming, I’d suggest you pick a resolution that works for most of your files (let’s say 800 points per file) and average dynamically based on the source length. Also, as the BBC tool does, I’d suggest to keep the data in integer values instead of using floats and specify the bit depth so you can then convert the data during rendering on a range of -1/+1. This approach results in much smaller files and faster parsing. Finally you’re better off using a binary format but whatever you do, make sure to store the file gzipped to save network transfer time.
Conclusion
- Pre-calculate waveforms server side.
- It’s not that complicated, use FOSS such as the BBC’s or SoX/FFmpeg.
- Tweak the sampling window based on your use cases or the file duration.
- Leverage modern cloud solutions such as PubSub/SQS and on-demand cloud functions to make sure you can ingest a large volume and keep the costs low.
Next, we will cover rendering waveforms.